Evolutionary algorithms
AI that just becomes better
2 Feb 2022 · 3 minute read

Have you ever wondered how some algorithms just become better the more you use them, for example, better social media recommendations or highly personalized YouTube feeds? Today we’re looking at one of the many approaches one can take to achieve this: Evolutionary algorithms.
Evolutionary algorithms are inspired by the Darwinian theory that evolution is subject to a set of primal operations as the survival of the fittest, genome crossover, and random mutation as a result of adapting to the environment. They also rely on the fact that small improvements in the genome of individuals can, over time, using the technique of survival of the fittest, lead to greater advancements of the species. Being fit in such a population is highly subjective and is a function of the environment of the specific species. Gradually eliminating fewer fit members from the population and allowing, with a greater probability, the fittest to reproduce, will, over a number of epochs (the time unit in evolutionary algorithms), lead to an overall fitter population.
Using evolutionary algorithms in automated machine learning leverages the power of both evolution and statistics, since they mimic the trial and error performed by data scientists when approaching a project, and also follow the statistical fitter individuals, always pursuing the search in places where it is known that something is to be found. Also, they do not hesitate to explore new paths from time to time, leading to the well-known exploration-exploitation dilemma, which we’ll explain in depth in the following weeks.
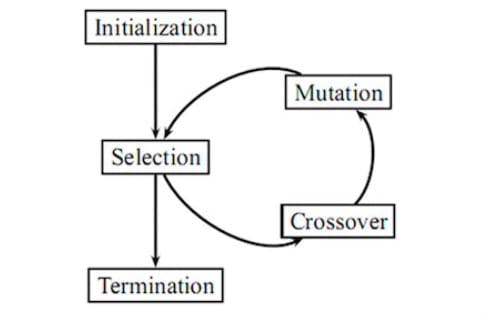
Looking at this flow of evolutionary algorithms, the approach seems natural, since, as human beings, we are accustomed to it. The flow is a simple way of searching through the tightest corners of the search space and providing untaught configurations. Provided enough time and the right crossover, mutation, and selection logic, evolutionary algorithms are able to converge to global optimums and yield the awaited result.
Using the concepts of evolutionary algorithms in automated machine learning, one can search through the configuration space more efficiently, finding gradually better methods. Genomes can be considered as different configurations and their fitness is some metric on the dataset, such as classification accuracy. Data engineering is also subject to evolutionary optimizations since the techniques of generating features can be combined in various ways in order to extract the most valuable information from the dataset. Both feature engineering and model training using evolutionary algorithms can lead to interesting results, subject to further analysis by data scientists or AutoML tools.
⬤
⬤
⬤
As also mentioned previously in this section, Evolutionary Algorithms have some basic operations that guarantee the coverage of the search space provided enough time, namely random initialization, selection, cross-over, and mutation. Let’s see how those 4 steps help find better neural network architectures:
Random initialization
Neural networks have a few parameters available for tuning, some of them being the number of layers and the count of neurons in each, activation functions, dropout rates, and the learning rate. During the initialization phase, the specifications of each neural network that is being built are randomly selected from the available pool, be it a list of predefined choices or a continuous interval. The randomness provides diversity in the population.
Selection
At each epoch, two chromosomes (in this case, neural networks) are randomly selected for crossover. Multiple selection procedures exist, each with empirically proven good performances. To name a few, random selection selects a random chromosome, tournament selection samples a k-sized random population and returns the best from it, and roulette selection, which randomly selects individuals with a probability directly proportional to their fitness.
CrossOver
After 2 chromosomes are sampled from the population, a cross-over is performed, also known as an XO operator, providing an offspring. For example, for each property of the neural network, the offspring either inherits it from one of its parents with a given probability or creates a combination of both (e.g. the average for the learning rate).
Mutation
After the offspring are generated, the mutation operator M is applied in order to slightly transform its properties. The transformation M(off) yields a mutated offspring. For example, the mutation can consist of random modifications in continuous parameters (selecting a different activation function) or random switches in discrete ones (increasing or decreasing the learning rate).
⬤
⬤
⬤
That was a short introduction to how AI algorithms can become better without much human input. At AI Flow we take evolutionary algorithms one step further and automate the whole flow from data to deployed models. Check it out!