Basic data preparation for Machine Learning
What to do before training a model
19 Jan 2022 · 3 minute read
The very core of every learning algorithm is data. The more, the better. Experiments show that for a learning algorithm to reach its full potential, the data that we feed to it must be as qualitative as it is quantitative. To achieve state of the art results in data science projects, the main material, namely data, has to be ready to be shaped and moulded as our particular situation demands. Algorithms that accept data as raw and unprocessed as it is are scarce and often fail to leverage the full potential of machine learning and of the dataset itself.
The road between raw data and the actual training of one model is far from straight and often requires various techniques of data processing to reveal insights and to emphasize certain distributions of the features.
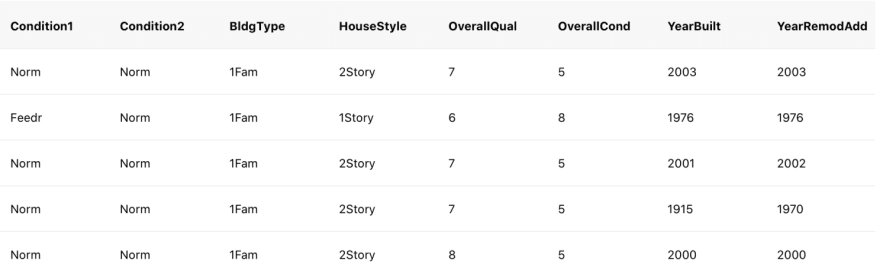
Take for example this dataset from the real estate business. It is by far an easy job to be able to accurately predict the final acquisition price of a house considering only the raw data. There is no way a generic algorithm could make a difference between ‘1Story’ and ‘2Story’ from the HouseStyle column or differentiate between two different value scales, like the year in the YearBuilt column and the mark in the OverallQual column.
Data preparation has the duty of building an adequate value distribution for each column so that a generic algorithm could learn features from it. Some examples are rescaling the values, turning text information into categorical or extracting tokens from continuous string values, like product descriptions. This post will give some insights into how to transform raw data into formats that make the most out of it.
Handling missing data
As the data producing sources are rarely perfect, raw datasets have missing values. Since generic algorithms cannot handle such cases and replacing them with a random value opens the possibility of obtaining any random output, methods have been implemented to replace them while keeping the data distribution in place, unmodified.
The basic solution is dropping the rows or columns that contain an excessive amount of missing fields, since replacing all the empty fields with the same default value might bias the model rather than create valuable insights. You might imagine that this approach is not optimal, since we don’t want to delete data that might prove itself valuable. Instead, setting missing values to the median of the column has, experimentally, provided good results, since it keeps a similar data distribution.
Handling outliers
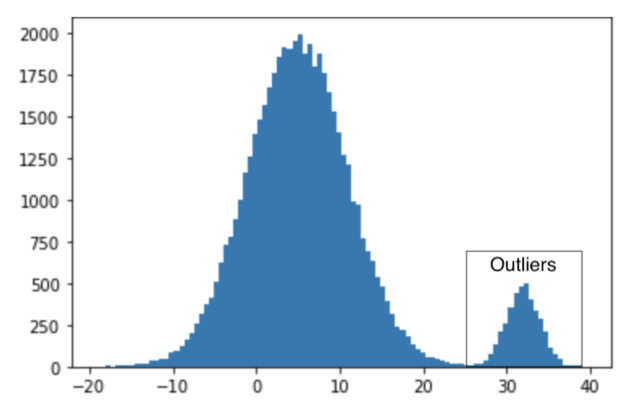
Outliers are data points that lie far away from the majority of data samples in the geometrical space of the distribution. Since these observations are far from the mean, they can influence the learning algorithm in an unwanted way, biasing it towards the tails of the distribution. A common way to handle outliers is Outlier Capping, which limits the range, casting a value X in the range [ m - std * delta , m + std * delta ], where m is the median value of the distribution, std the standard deviation and delta an arbitrarily chosen scale factor. This is how we would write this more formally:
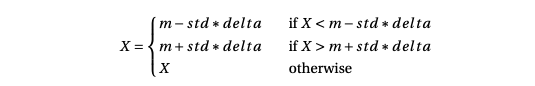
Creating polynomial features
There is often the case in machine learning when a feature is not linearly separable. Although more complex algorithms cope with the problem of non linearly separable search spaces, they might sacrifice accuracy over covering all the nonlinearities. Thus, creating polynomial features can help learning algorithms separate the search space with more ease, yielding better results in the end.
Generating the second degree polynomial of feature 1 and adding it to the dataset yields a better representation of the geometrical data space, thus making it easier to be split. Although this is a shallow example, it clearly illustrates the importance of polynomial features in machine learning. On a large scale, polynomials of multi-feature combinations are taken into consideration for generating even more insights from the data.
⬤
⬤
⬤
Those were just a few data processing steps to consider. At aiflow.ltd, we automatically process the data with many more steps, to make sure the prediction quality of our automated algorithms is the best we can achieve. If you’re curios to find out more, subscribe to our newsletter on aiflow.ltd