Word2Vec
How to transform words into numbers without context loss
20 Oct 2020 · 6 minute reads
People write books, blog posts, articles and send thousands of messages daily. They are able to transfer a lot of knowledge and meaning through text, provided that the reader understands the meaning of the words. What if we can transfer this knowledge to a computer and enable it to understand the semantics behind a list of words? By doing so, we enable computers to learn and understand text, draw conclusions and even generate sequences that actually make sense.
The reason to do so might not be clear from the beginning. Why would we want to create some sort of encodings that computers understand? Do you remember your recent Google search that kindly offered you some autocomplete options or the chatbot you chatted with to the last time you made a restaurant reservation? These might be some of the many reasons to look into a way to convert text to formats computers would understand.
⬤
⬤
⬤
Since computers don't understand words, but only numbers, there must be some way to convert a sentence into a list of words. One can simply transform "I think I understand machine learning" to the list [0, 1, 0, 2, 3, 4], based on the index of the first occurrence of the word in the sentence. While this is a valid input for a computer, it does not offer much insight into the actual semantics of the sentence. In the absence of a structure, computers are not able to learn representations and patterns from data. There must be a way to encode a given corpus of text into a sequence of n-dimensional vectors, one for each word while preserving the meaning and patterns we see in the texts we read in our daily life.
"Cells that fire together wire together" - Donald Hebb
You've probably heard this quote a few times until now and it applies perfectly to the use case of understanding natural language. You have probably noticed (if not, empirical studies clearly did), that some words are often coupled together, rather than alone in sentences. As a very shallow example, "cat" and "dog" are probably more often together than "cat" and "coffee" are. This shows that we can somehow, given a center word, predict the likelihood of other words to be in its context. We can learn a representation that will put "cat" closer to "dog" than to "coffee" in our n-dimensional space. More formal, the euclidian distance between the representations of "cat" and "dog" will be shorter than the same distance between "cat" and "coffee".
This drives us to what is known to be the n-gram model when we consider n context words around a center one. Using this idea, a training set is built with tuples of the form (A, B), where A and B are one-hot encoded vectors. I'll briefly explain this idea. Given a vocabulary V, A has id a and B has id b, the one-hot encoded vector of A would be a list of zeros of the size of V, with 1 only on the position a. The same goes with B and that basically signals the presence of that particular word in that vector.
Given this long list of (center, context) word pairs, we would like to train a special type of neural network, namely an autoencoder, that, given the center word, should accurately return a list with the probabilities of each word in the vocabulary to be in its surrounding. In the training process, we shrink the network in the middle, creating an embedding layer. This process makes the network learn the "essence" of every word, forcing it's meaning and semantic to fit into a fixed size embedding vector, small enough so we can use it for future tasks.

The model can be very simply represented by two matrices; the encoder matrix, called W1, and the decoder matrix, called W2. Suppose that X is a one-hot encoded version of a word, the word2vec encoding of it is the product X*W1. Given the encoding E of some word, the likelihood of any other word to be in its context is the product E*W2, turning the encoding into a set of probabilities for each word in the vocabulary.
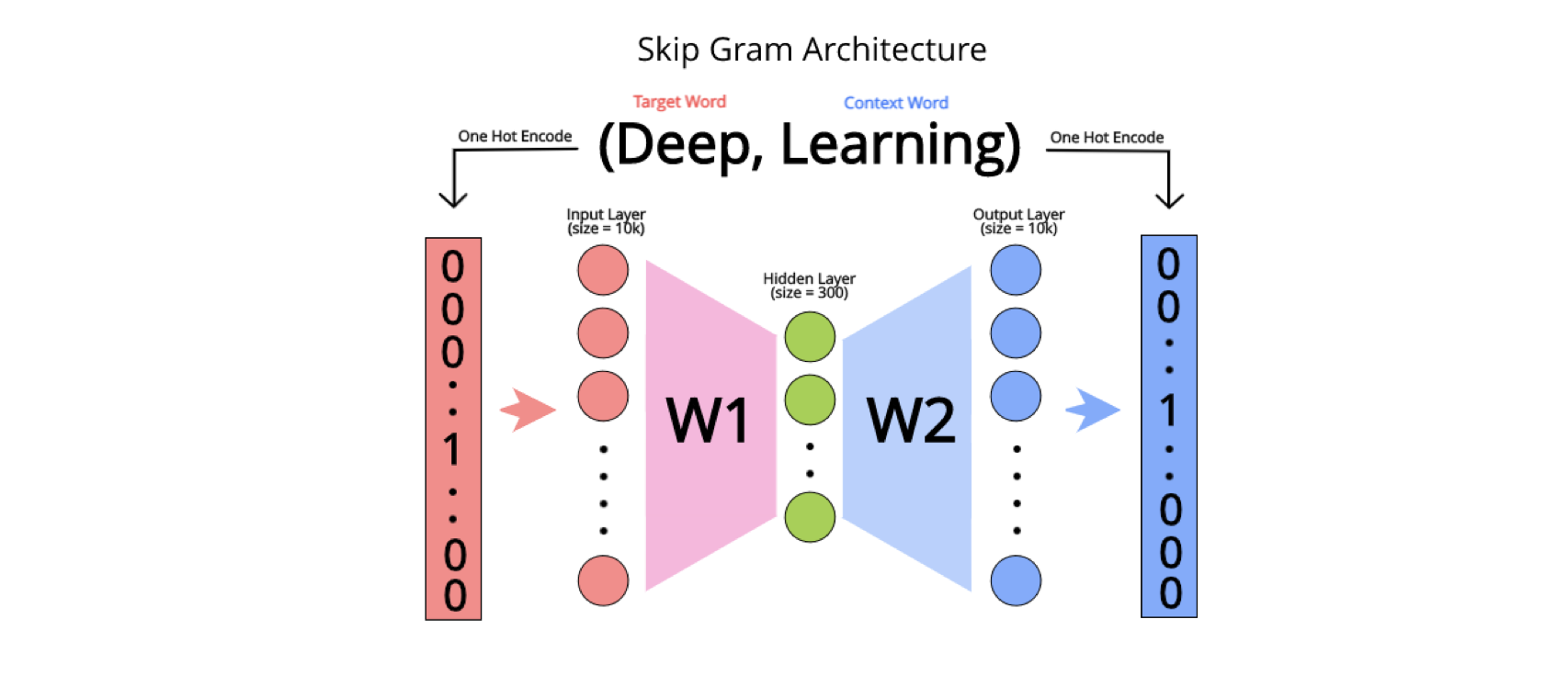
The model is conventionally learned using backpropagation, trying, at every step, to teach it to assign greater probabilities to the context words of a given center word rather than to other random words in the vocabulary.
The technique described above is a simple yet smart way of transforming words into computable structures, as numeric arrays. The results we obtain might be some random guesses at the first sight, but when we properly use them, we can find various interesting things. Without any additional processing, we can find associations in the n-dimensional space that are simple for us humans but not so obvious for computers. For example, we can ask the general question: What is to X as A is to B? and the model will give some interesting outputs:



Once we have a smart way of embedding words while capturing their semantics and logic, a wide variety of tasks can be done, since we have text data all around the place. We can generate summaries from big texts, do machine translation, and create our own Google translate and, what's most interesting, generate text given a large enough dataset to learn from.